
Transfer Learning
리뷰 데이터를 긍정과 부정으로 이진 분류하는 긍부정 판별 모델을 만들어야 한다고 가정해보자. 그런데 이 때 모델 학습에 쓸 수 있는 수집된 데이터가 1,000개 미만이라면 어떻게 해야할까?
적은 양의 데이터로는 당연히 성능 좋은 모델을 만들 수 없다. 이렇게 데이터가 적을 때 고려해야할 사항이 바로 Pre-trained 모델(사전 학습 모델)을 활용하는 Transfer Learning(전이 학습)이다.

많은 데이터로 미리 학습된 모델을 사전 학습 모델이라 한다. 구글이나 페이스북과 같은 대기업에서 엄청난 양의 데이터를 학습한 사전 학습 모델들을(ex. BERT) 오픈 소스로 공개하고 있다. 또한 이렇게 공개된 사전 학습 모델을 기반으로 더 개선된 사전 학습 모델들이 나오고 있기 때문에 해결하고자 하는 테스크 분야(NLP, CV, ..)에서 어떤 사전 학습 모델이 있는지 파악해놔야 한다.
Transfer Learning of NLP
NLP 분야에서 사전 학습 모델들은 크게 두가지로 나뉜다. Word Embedding과 Language Model이다.
- Word Embedding은 NLP에서 가장 기초적인 전이 학습 방식이다. 사전 학습된 언어 사전을 활용해 단어 토큰들을 벡터화한다. (ex. Word2Vec, GloVe...)
- Language Models (BERT, ELMO같은 언어 모델들은 Sentence Embedding을 계산할 수 있다. 전이 학습 과정에서 새로운 데이터를 input했을 때, 사전 학습된 LM의 Sentence Embedding을 받아 우리가 붙인 특정 테스크 해결을 위한 모델이 연산을 하게 된다.
사전 학습 언어 모델들은 라벨이 없는 무수하게 많은 텍스트 데이터들을 학습한다. 이를 통해 언어에 대한 전반적인 이해를 비지도 학습하는 것이다.
언어에 대한 전반적인 이해를 갖고 있는 사전 학습 모델을 가져와서 전이 학습에 사용하고 싶다면, 아래 사항들을 고려해봐야 한다.
내가 풀려는 문제(Task, Domain)가 이 모델에 적합한지 파악해야한다.
- 내가 풀고 싶은 것은 영화 리뷰 데이터 긍부정 판별 모델이다. 그런데 사전 학습 모델은 뉴스 기사 텍스트만 주구장창 사전 학습해왔다면? 나의 문제를 잘 해결할 수 있는 모델을 만들 수 있는가 고민해봐야한다.
적은 양이라도 어느 정도의 데이터를 확보해야한다.
- 사전 학습 언어 모델이 언어에 대한 전반적인 이해를 갖고 있더라도, 이 사전 학습 모델에게 '내가 앞으로 너를 이용해서 어떤 문제를 풀거야!'를 알려줄 수 있을만큼의 데이터를 확보 해야 한다.
- 감성 분류 문제인지, 다음 문장 예측 문제인지, 문장 간 유사도를 구하는 문제를 해결할 것인지 본인이 풀려는 문제에 알맞는 데이터셋을 가지고 downstream 단계의 학습을 시켜야 한다.
확보한 데이터에 사전 학습 모델을 어떻게 적용할 것인지 알아내야 한다.
- 전이 학습을 위해 사전 학습 모델을 가져올 때, 모든 가중치를 사용하는 것이 아니다. 사전 학습 모델의 최종 출력값을 뽑는 가중치 층을 제외하고 사용해야한다.
- 왜? 최종 출력값의 경우에 각 문제마다 형태가 모두 다르기 때문이다.
- ex) 텍스트 유사도 모델의 출력층 → 유사도 출력
- ex) 감정 분석 모델의 출력층 → 긍정/부정 이진 분류 결과 출력
BERT를 활용한 전이 학습 기법 2가지
사전 학습한 가중치를 활용하는 방법 두가지 중 어떤 방법으로 전이 학습을 할 것인가 선택해야 한다.
- 피쳐 뽑기(Feature Extraction)
BERT를 위 그림처럼 블랙박스 함수라고 생각하고 BERT가 내뱉는 vector를 다른 머신러닝 모델의 input으로 쓴다. 이 경우에는 BERT의 파라미터(노란색)는 고정되어 변하지 않고, 빨간색으로 얹힌 새 모델만 가진 데이터를 가지고 학습이 된다.
즉, 사전 학습 모델이 가지고 있는 기존의 가중치(weight)는 Freeze(동결)하고, 전이 학습을 위해 사전학습 모델의 출력층에 붙인 모델만 현재 가지고 있는 데이터로 학습을 시킨다.
- 재학습(Fine-tuning)
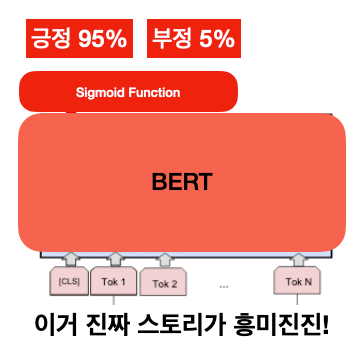
이 방식은 데이터가 조금 더 많이 있을 때 쓰면 좋은 방식이다. 사전 학습 모델인 BERT의 파라미터(가중치)도 가지고 있는 데이터를 통해 재학습 시키는 것인데, BERT 뿐만 아니라 그전부터 다양한 머신러닝 문제에서 Transfer-Learning의 힘을 빌릴 때 많이 쓰이는 기법이다. 여기서 핵심은 아무런 머신러닝 모델을 붙일 수 있는 게 아니라 Sigmoid function이나 multi-layer perceptron(MLP)처럼 Back-propagation(역전파)이 가능해야 한다. 안 그러면 같은 cost function으로 기존 BERT 모델이 재학습되지 않기 때문이다.
즉, 사전 학습 모델이 가지고 있는 가중치(weight)와 전이 학습을 위해 사전학습 모델의 출력층에 붙인 모델 모두 현재 가지고 있는 데이터로 학습을 시키는 방식이다.
Reference
Week 27 - 전에 배운걸 잘 써먹어야 산다 Transfer Learning
- 그림 1 (전이 학습이란?)
- Transfer Learning에 대한 내용
- 그림 3 (BERT의 전이학습)
- 그림 4 (BERT의 전이학습)
[책] (텐서플로 2와 머신러닝으로 시작하는)자연어 처리 : 로지스틱 회귀부터 BERT와 GPT2까지
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)
- 그림 2 (BERT를 사용해 전이학습을 진행한 분류 모델)
'원티드 프리온보딩 AI•ML (NLP)' 카테고리의 다른 글
| Week2-1. Pytorch tutorial (1) - Tensor (0) | 2022.04.07 |
|---|---|
| Week1-3. NLG와 extractive summarization task (4) | 2022.02.23 |
| Week1-2. NLU와 Semantic Textual Similarity (5) | 2022.02.22 |
| NLP와 벤치마크 데이터셋 (0) | 2022.02.22 |
| Week1-1. NLP Sub-Task 탐색 (3) | 2022.02.21 |