1. 선형함수가 무엇인가?
- y=x , y=ax , y=ax+b 와 같은 함수
- 출력이 입력의 상수배만큼 변하는 함수
2. 신경망의 구조
- 가장 기본적인 신경망인 (다층) 퍼셉트론은 입력층, 은닉층, 출력층으로 구성되어 있다.
- 여기서 딥러닝의 성능을 더 향상시키기 위해서는 은닉층을 계속 추가해야한다.
- 은닉층과 출력층은 현재 노드에서 다음 노드로 가중치를 곱한 합인 출력값을 넘기는데, 이 때 사용되는 것이 활성화 함수이다 .
- 활성화 함수에 따라 현재 노드에서 출력된 값이 다음 층의 노드로 넘어가느냐 마냐를 결정한다.
3. 여러 은닉층을 가진 신경망
- 딥러닝 모델의 성능 향상을 위해 여러 은닉층을 쌓는데, 이 때 이 은닉층이 선형 활성화 함수를 가질 경우
- 선형 함수는 아무리 많은 은닉층을 쌓아도, 그 결과가 하나의 층을 쌓는 것과 같다.
- 즉, 딥러닝 모델의 성능 향상을 목적으로 여러 은닉층을 쌓아도, 활성화 함수를 선형 활성화 함수로 지정하면, 그 혜택을 받지 못한다는 것.
- ex.
- f(x)=Wx라는 선형 활성화 함수
- 3개의 은닉층을 쌓으면, y(x)=f(f(f(x))) → 식으로 표현하면, W × W × W × x
- W의 세 제곱값을 k라고 정의해버리면, 이 식은 y(x)=kx와 같이 다시 선형 함수로 표현이 가능
- 즉, 선형 활성화 함수로는 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이를 줄 수 없다.
- 따라서 여러 층으로 쌓은 은닉층을 살리면서 딥러닝 모델의 성능을 향상시키기 위해서는 은닉층의 활성화 함수로서 '비선형 활성화 함수'를 사용해야 한다 .
4. 비선형 활성화 함수의 종류
- ReLU (주로 은닉층에서 많이 활용하는 비선형 활성화 함수)
- 음수를 입력하면 0을 출력하고, 양수를 입력하면 입력값을 그대로 반환
- 수식은 f(x)=max(0,x)
- 특정 양수값에 수렴하지 않으므로 깊은 신경망에서 시그모이드 함수보다 훨씬 더 잘 작동한다.
- 시그모이드 함수와 하이퍼볼릭탄젠트 함수와 같이 어떤 연산이 필요한 것이 아니라 단순 임계값이므로 연산 속도도 빠르다.
- 그러나. 입력값이 음수면 기울기도 0 → 기울기 소멸..

- Leaky ReLU (주로 은닉층에서 많이 활용하는 비선형 활성화 함수 2)
- 입력값이 음수일 경우에 0이 아니라 0.001과 같은 매우 작은 수를 반환
- 수식은 f(x)=max(ax,x)
- a는 하이퍼파라미터로 Leaky('새는') 정도를 결정. 일반적으로 0.01 값을 가진다.
- '새는 정도' : 입력값이 음수일 때의 기울기를 의미한다.

- Sigmoid (은닉층의 활성화 함수로서 '지양'되는 함수)
- 출력층의 뉴런에서 주로 사용
- 이진 분류 문제를 해결하기 위한 딥러닝 모델에서 출력층의 활성화함수로 주로 사용된다.

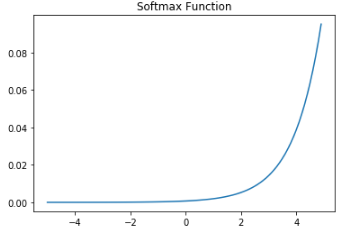
- Softmax
- 출력층의 뉴런에서 주로 사용
- 다중 분류 문제(세 가지 이상의 (상호 배타적인) 선택지)를 해결하기 위한 딥러닝 모델에서 출력층의 활성화 함수로 주로 사용된다.
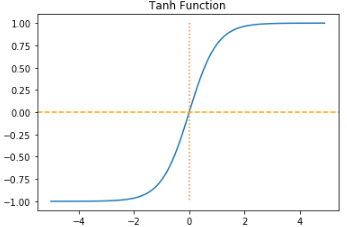
- Tanh (하이퍼볼릭 탄젠트) : 입력값을 -1과 1사이의 값으로 변환
5. 기울기 소실 문제
- 신경망 학습 과정
- 입력에 대해서 순전파(forward propagation) 연산을 하고,
- 순전파 연산을 통해 나온 예측값과 실제값의 오차를 손실 함수(loss function)을 통해 계산하고,
- 이 손실(loss)을 미분을 통해서 기울기(gradient)를 구하고,
- 이를 통해 역전파(back propagation)를 수행하면서
- 손실을 최소화하는 가중치 값을 찾아 업데이트 한다.
- Sigmoid(시그모이드) 함수의 기울기 소실 문제
- 문제 발생 과정 :
- 3. 손실(Loss)값을 미분을 통해 기울기를 구하고(특히 이 부분) → 4. 이를 통해 역전파를 수행할 때 기울기 소실 문제가 발생한다.
- 왜 시그모이드 함수가 특히 기울기 소실 문제가 발생하는가?

- 시그모이드 활성화 함수의 양끝단 (0과 1에 가장 가까운 부분)을 보면, 기울기가 굉장히 완만하다.
- 이 부분에서 미분을 통해 기울기를 구하면 → 그 값은 거의 0에 수렴한다.
- 이렇게 구해진 0에 가까운 기울기를 역전파 과정에서 곱하는데 → 그럼 그 값도 거의 0에 수렴한다.
- → 신경망 모델의 앞단으로 역전파를 하면 할수록 점점 더 기울기가 소실되는 문제가 발생
- 그럼 결과적으로 가중치를 업데이트 할 수 없기 때문에, 신경망 학습이 불가능해진다.

- 위 그림 설명
- 역전파가 시작되는 출력층에 가까운 은닉층은 기울기 전파가 상대적으로 잘 되지만,
- 앞단으로 갈수록 점점 기울기가 소실되고 있는 모습.
- 이런 이유 때문에 시그모이드 함수를 은닉층 활성함수로 사용하는 것을 지양한다.
6. 출력층의 활성화 함수와 비용함수(오차함수, 손실함수)의 관계
| 해결 문제 |
활성화 함수 |
비용 함수 (Loss) |
| 이진 분류 |
시그모이드 |
nn.BCELoss() |
| 다중 클래스 분류 |
소프트맥스 |
nn.CrossEntropyLoss() |
| 회귀 |
없음 |
MSE |
- 주의할 점 : nn.CrossEntropyLoss()는 softmax 함수를 이미 포함하고 있다.
Reference
